모델 훈련 및 과적합
선형 회귀, 경사 하강법, 규제 모델(Ridge, Lasso), 로지스틱 및 소프트맥스 회귀
Summarization
- 모델 훈련의 핵심은 비용 함수(Cost Function)를 최소화하는 파라미터를 찾는 것임.
- 경사 하강법(Gradient Descent)은 반복적인 최적화를 통해 전역 최솟값에 도달하는 범용적인 알고리즘임.
- 모델의 과대적합을 방지하기 위해 릿지(Ridge), 라쏘(Lasso), 엘라스틱넷(Elastic Net)과 같은 규제 기법을 적용함.
- 분류 문제에서는 로지스틱 회귀와 다중 클래스를 위한 소프트맥스 회귀를 사용함.
선형 회귀 (Linear Regression)
데이터를 가장 잘 설명하는 “직선”을 찾는 알고리즘임.
- 모델 예측: $\hat{y} = \theta_0 + \theta_1x_1 + \dots + \theta_nx_n$
- 비용 함수 (MSE): 예측값과 실제값 차이의 제곱 평균을 최소화하는 것이 목표임.
- 정규 방정식 (Normal Equation): 미분을 통해 비용 함수를 최소화하는 $\theta$를 직접 구하는 공식이지만, 특성이 많아지면 계산량이 급증함.
경사 하강법 (Gradient Descent)
산골짜기에서 안개가 꼈을 때, 가장 가파른 내리막을 따라 내려가는 것과 같음.
- 기본 원리: 현재 위치에서 비용 함수의 기울기(Gradient)를 구하고, 반대 방향으로 조금씩 이동하며 최솟값을 찾음.
- 학습률 (Learning Rate): 한 번에 얼마나 이동할지 결정하는 상수로, 너무 크면 발산하고 너무 작으면 시간이 오래 걸림.
- 종류:
- 배치 경사 하강법 (Batch GD): 전체 데이터를 사용 (정확하지만 느림).
- 확률적 경사 하강법 (SGD): 매 단계 하나의 샘플만 사용 (빠르지만 불안정함).
- 미니배치 경사 하강법 (Mini-batch GD): 일정 크기의 묶음(Batch)을 사용 (속도와 안정성의 균형).
경사 하강법 진행 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.scatter(X, y)
n_iterations = 1000
for iteration in range(n_iterations):
if iteration < 10:
y_predict = X_new_b.dot(theta)
plt.plot(X_new, y_predict, "r-")
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
plt.xlabel("$x_1$")
plt.axis([0, 2, 0, 15])
plt.title(f"eta = {eta}")
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X_new]
theta = np.random.randn(2,1)
plt.figure(figsize=(10,4))
plt.subplot(121); plot_gradient_descent(theta, eta=0.1)
plt.subplot(122); plot_gradient_descent(theta, eta=0.5) # 발산하는 경우
plt.show()
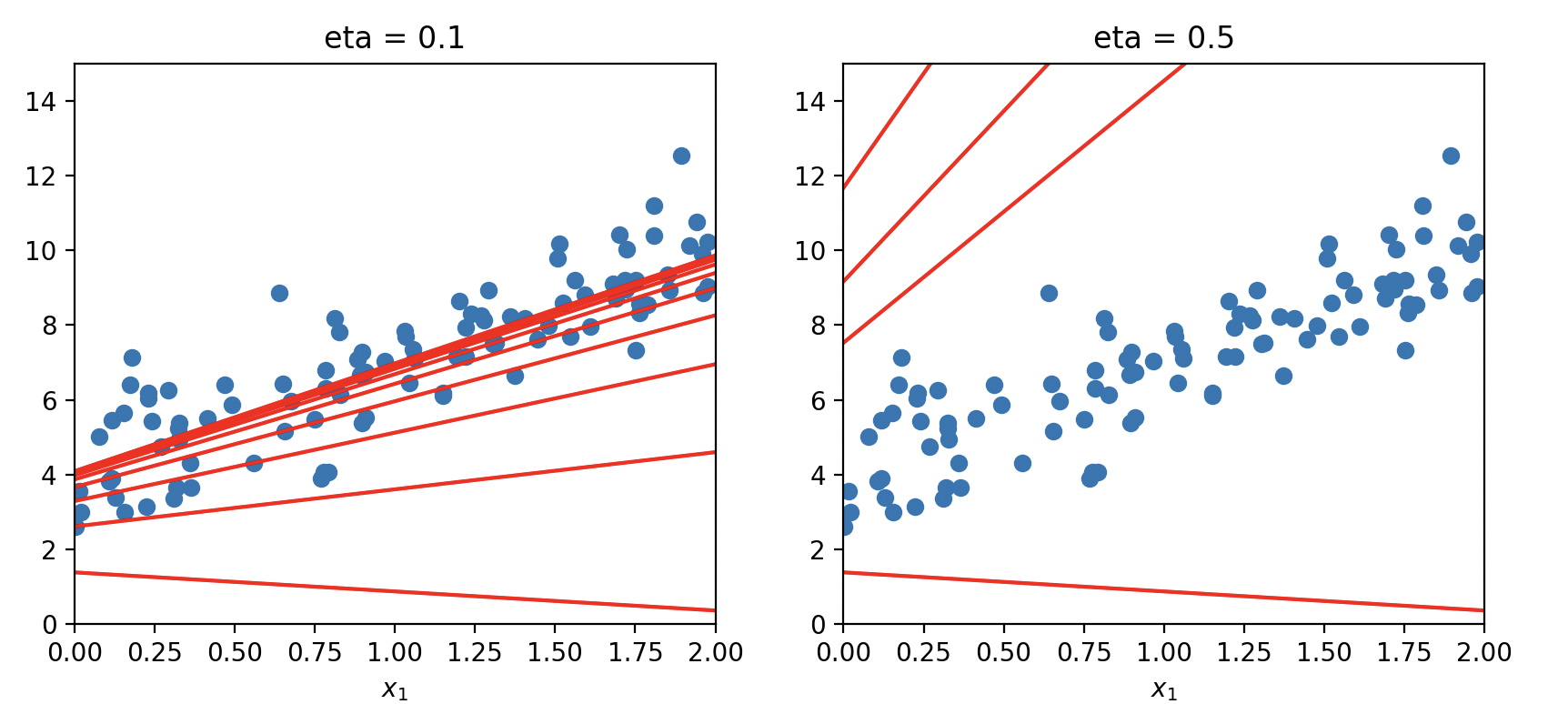
- 결과적으로, 학습률에 따라서 학습 성공 유뮤가 나올 수 있음을 보여줌.
- $\eta=0.1$ 일때, 보폭이 적절하여 반복이 진행됨에 따라 빨간색 회귀선이 데이터의 중심(최적점)으로 안정적으로 수렴함.
$\eta=0.5$ 일때, 보폭이 커서 최적점도 지나고, 선들이 데이터데어 멀어지는 발산(Divergence) 현상이 발생하여 학습에 실패하는 모습을 보임.
다항 회귀와 규제 모델
단순 직선으로 설명하기 힘든 비선형 데이터를 다루고 과대적합을 막는 방법임.
다항 회귀 (Polynomial Regression)
- 각 특성의 거듭제곱을 새로운 특성으로 추가하여 선형 모델을 훈련시키는 기법임.
- 차수가 너무 높으면 훈련 데이터에만 너무 맞춰지는 과대적합이 발생함.
선형 모델의 규제 (Regularization)
모델이 너무 복잡해지지 않도록 가중치(Weight)에 제약을 거는 방법임.
- 릿지 회귀 (Ridge): 가중치의 제곱합(L2)을 페널티로 부여함. 가중치를 0에 가깝게 만들지만 완전히 0이 되지는 않음.
- 라쏘 회귀 (Lasso): 가중치의 절댓값 합(L1)을 페널티로 부여함. 중요하지 않은 특성의 가중치를 완전히 0으로 만들어 특성 선택 효과가 있음.
- 엘라스틱넷 (Elastic Net): 릿지와 라쏘를 절충한 형태임.
조기 종료 (Early Stopping)
- 검증 에러가 최솟값에 도달했을 때 훈련을 중지하는 기법임.
- “공짜 점심”이라 불릴 만큼 간단하면서도 강력한 규제 방법임.
분류를 위한 회귀
숫자 예측을 넘어 클래스를 분류하는 알고리즘임.
로지스틱 회귀 (Logistic Regression)
- 샘플이 특정 클래스에 속할 확률을 추정함 (0과 1 사이).
- 시그모이드 함수 (Sigmoid): 출력값을 확률로 변환하는 활성화 함수임.
- 결정 경계 (Decision Boundary): 확률이 0.5가 되는 지점을 기준으로 클래스를 나눔.
소프트맥스 회귀 (Softmax / 다항 로지스틱 회귀)
- 클래스가 3개 이상인 다중 분류 상황에서 사용함.
- 각 클래스에 대한 점수를 계산한 뒤, 소프트맥스 함수를 통해 합이 1이 되는 확률 분포로 만듦.
크로스 엔트로피 (Cross Entropy)
- 모델이 예측한 확률 분포와 실제 타깃 분포 사이의 차이를 측정하는 비용 함수임.
- 예측이 틀릴수록 값이 급격히 커지므로, 모델이 올바른 방향으로 학습하도록 유도함.
결론
- 머신러닝 모델 훈련은 적절한 알고리즘 선택 -> 경사 하강법을 통한 최적화 -> 규제를 통한 일반화 성능 확보의 과정을 거침.
- 데이터의 특성에 따라 릿지나 라쏘 중 무엇을 쓸지, 다항 회귀의 차수를 어떻게 조절할지가 성능의 핵심이라 할 수 있음..
This post is licensed under CC BY 4.0 by the author.