학습 및 모델 최적화
머신러닝 훈련 데이터의 질, 샘플링 문제, 과대적합/과소적합, 모델 검증
Summarization
- 머신러닝 모델의 성능은 알고리즘만큼이나 데이터의 품질(Quality)과 샘플링 전략에 크게 의존함.
- 모델의 복잡도와 데이터 크기 사이의 균형을 맞추지 못하면 과대적합(Overfitting) 또는 과소적합(Underfitting) 문제가 발생함.
- 이를 해결하기 위해 규제(Regularization), 검증 세트(Validation Set) 구성, 교차 검증(Cross-Validation) 등의 최적화 기법을 사용함.
학습 데이터
단순히 데이터를 넣는다고 학습이 되는 것이 아님. “Garbage In, Garbage Out” 원칙에 따라 데이터의 결함을 파악하는 것이 선행되어야 함.
충분하지 않은 훈련 데이터량
- 대부분의 머신러닝 알고리즘이 잘 작동하려면 수천 개에서 수백만 개의 샘플이 필요함.
- 데이터가 적으면 모델이 통계적 노이즈를 패턴으로 오인할 확률이 높음.
대표성 없는 훈련 데이터 (Sampling Bias)
- 일반화가 잘 되려면 새로운 사례를 잘 대표하는 데이터가 필요함.
- 샘플링 잡음(Sampling Noise): 샘플이 너무 작아 우연에 의한 왜곡이 발생.
- 샘플링 편향(Sampling Bias): 추출 방법 자체가 잘못되어 특정 집단이 배제됨. (예: 1936년 미국 대선 당시 전화 보유자에게만 여론조사를 실시해 예측 실패한 사례)
낮은 품질의 데이터 및 특성 공학
- 데이터 정제: 이상치(Outlier)를 제거하거나 결측치(Missing Value)를 채우는 과정이 필수적임.
- 특성 선택(Feature Selection): 가지고 있는 특성 중 가장 유용한 것을 선택.
- 특성 추출(Feature Extraction): 특성을 결합하여 새로운 유용한 특성을 만듦 (예: 차원 축소 - PCA).
모델의 일반화: Overfitting vs Underfitting
모델이 훈련 데이터에는 잘 맞지만 새로운 데이터에서 성능이 낮은 경우를 해결하는 것이 핵심임.
과대적합 (Overfitting)
훈련 데이터의 디테일과 노이즈까지 학습하여 일반화 성능이 떨어지는 상태.
평가 및 검증 (Testing and Validating)
모델이 실전에 투입되었을 때의 성능을 예측하기 위해 데이터를 분할 관리함.
훈련/테스트 세트 (Train/Test Split)
- 보통 8:2 또는 7:3 비율로 분할.
- 테스트 세트에서 발생하는 에러율을 일반화 오차(Generalization Error)라고 함.
검증 세트와 하이퍼파라미터 튜닝
- 하이퍼파라미터를 테스트 세트로 튜닝하면, 모델이 테스트 세트에 과적합되어 실제 서비스 시 성능이 떨어지는 데이터 스누핑(Data Snooping) 문제가 발생함.
- 따라서 훈련 세트 -> 검증 세트(성능 평가) -> 테스트 세트(최종 확인)의 3단계 절차가 표준임.
교차 검증 (K-Fold Cross-Validation)
데이터가 부족하여 검증 세트를 크게 잡기 어려울 때 사용.
모델 복잡도 시각화
다항 회귀(Polynomial Regression)의 차수(Degree)를 조절하며 최적의 모델을 찾는 과정을 시각화 함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# 1. 비선형 샘플 데이터 생성
def true_fun(X):
return np.cos(1.5 * np.pi * X)
np.random.seed(0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
# 2. 모델 비교 (Underfitting, Good Fit, Overfitting)
degrees = [1, 4, 15]
plt.figure(figsize=(14, 5))
for i, degree in enumerate(degrees):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
poly_features = PolynomialFeatures(degree=degree, include_bias=False)
lr = LinearRegression()
pipeline = Pipeline([("poly", poly_features), ("lr", lr)])
pipeline.fit(X[:, np.newaxis], y)
# 교차 검증 점수 (MSE)
scores = cross_val_score(pipeline, X[:, np.newaxis], y,
scoring="neg_mean_squared_error", cv=10)
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function", linestyle="--")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.title(f"Degree {degree}\nMSE: {-scores.mean():.2e}")
plt.legend(loc="best")
plt.show()
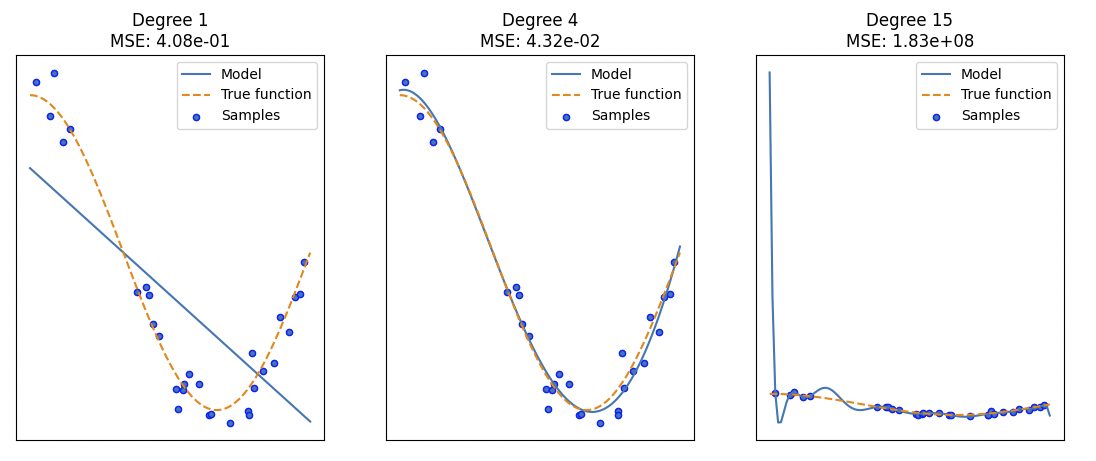
- Degree 1,4,15 순으로 과소적합, 최적 모델, 과대 적합의 학습 양상을 보임.
- 복잡도는 왼쪽에서 오른쪽으로 가면서 높아지고 MSE 값은 높음, 낮음, 매우 높음을 상대적으로 보임.
- 결과적으로 머신러닝 모델의 최적화의 목표는 편향과 분산 사이의 trade-off를 잘 조절하여, 훈련 세트 뿐 아니라 보지 못한 데이터에서도 잘 작동하는 모델을 만든는 것임.
This post is licensed under CC BY 4.0 by the author.