Word Embedding
One-hot encoding, Word Embedding(CBOW & Skip-gram), GloVe
Intro
2013년, Google 사에서 다음과 같은 연구가 발표되었다.
Efficient Estimation of Word Representations in Vector Space, Mikolov et al., 2013
본 논문의 Word2Vec model은 CBOW와 Skip-gram Arichitecture를 통해 효율적으로 단어의 벡터 표현을 학습하는 방법을 제시하였다. 이는 NLP(자연어처리) 분야에 큰 영향을 미쳤고, 현재까지도 많은 연구 및 산업에 사용되는 BERT, GPT 등 Transformer model의 근간이 되었다.
해당 글에서는 Word Embedding 이전에 사용되었던 One-hot encoding과, Word Embedding(with CBOW & Skip-gram), Word2Vec과 가장 많이 쓰이던 단어 임베딩 기술인 GloVe에 대해 다뤄보겠다.
One-Hot Encoding
한줄 요약 : 각 단어를 고유한 벡터로 표현하는 방법으로, 생성되는 벡터에서 하나의 요소만 1이고 나머지는 0으로 표현되는 벡터를 생성하는 과정
NLP, 이미지처리, 신호처리 등의 분야에서 사용될 수 있으며 NLP에서는 주로 텍스트 데이터를 수치 데이터로 변환할 때 사용된다. Word Embedding 이전, 구현이 간단하고 명확하여 가장 많이 쓰였었다.
벡터를 생성하는 방식은 다음과 같다.
예를 들어, [‘Ronaldo’,’Messi’,’Son’,’Ohtani’] 라는 단어집이 있다. 각 단어의 위치 (인덱스 즉, 순서를 부여하여 할당함 ex.Ronaldo -> 0, Messi -> 1) 에 해당하는 부분만 1, 나머지는 0으로 채워 벡터를 생성한다.
1
2
3
4
'Ronaldo' = [1,0,0,0]
'Messi' = [0,1,0,0]
'Son' = [0,0,1,0]
'Ohtani' = [0,0,0,1]
단어 집합의 크기가 4 이므로, 각 단어는 4차원 벡터로 표현된다. 이렇게 생성된 벡터는 텍스트 분류, 생성, 변역, 임베딩 레이어의 입력값으로 사용된다.
간단하고 사용도 편하지만, 딥러닝 모델등에 넣기에는 데이터의 크기가 발목을 잡게 된다.
단어집의 크기가 지금은 4개지만 크기가 커질수록 벡터의 크기도 커지는데, 커질수록 0의 값은 많아지지만 1의 값은 단 하나이다.
즉, 희소한 벡터를 생성 한다라고 말할 수 있다.
또한, 단어 간의 유사성을 반영하지 못하는데, 예를들어, ‘Football’, ‘Soccer’는 의미적으로 유사하지만 One-hot encoding에서는 유사한 것을 표현하지 못하고 아예 다른 벡터로써 표현된다. 이러한 문제점들을 개선한 것이 Word Embedding 방식이다.
cf. 텍스트 데이터를 수치 데이터로 바꾸는 이유?
인간만 이해할 수 있는 자연어(인간 언어)를 컴퓨터가 이해할 수 있는 수치로 바꾸는 과정이 필요하기 때문.
Word Embedding
Word Embedding은 단어를 고차원 공간의 밀집 벡터로 변환하여 단어 간 유사성을 학습하는 기법이다. 이 방법 중 하나로 주로 사용되는 것이 Word2Vec과 GloVe이다.
Word2Vec
해당 모델의 가장 큰 특징은 단순한 학습 방법을 사용해서 계산량이 매우 적은 편이라 더 많은 양의 데이터를 다룰 수 있다는 것이다. Word2Vec은 학습 시 두 모델 중 하나로 학습을 할 수 있는데, 그것이 Continuous Bag-Of-Words(CBOW)와 Skip-gram이다.
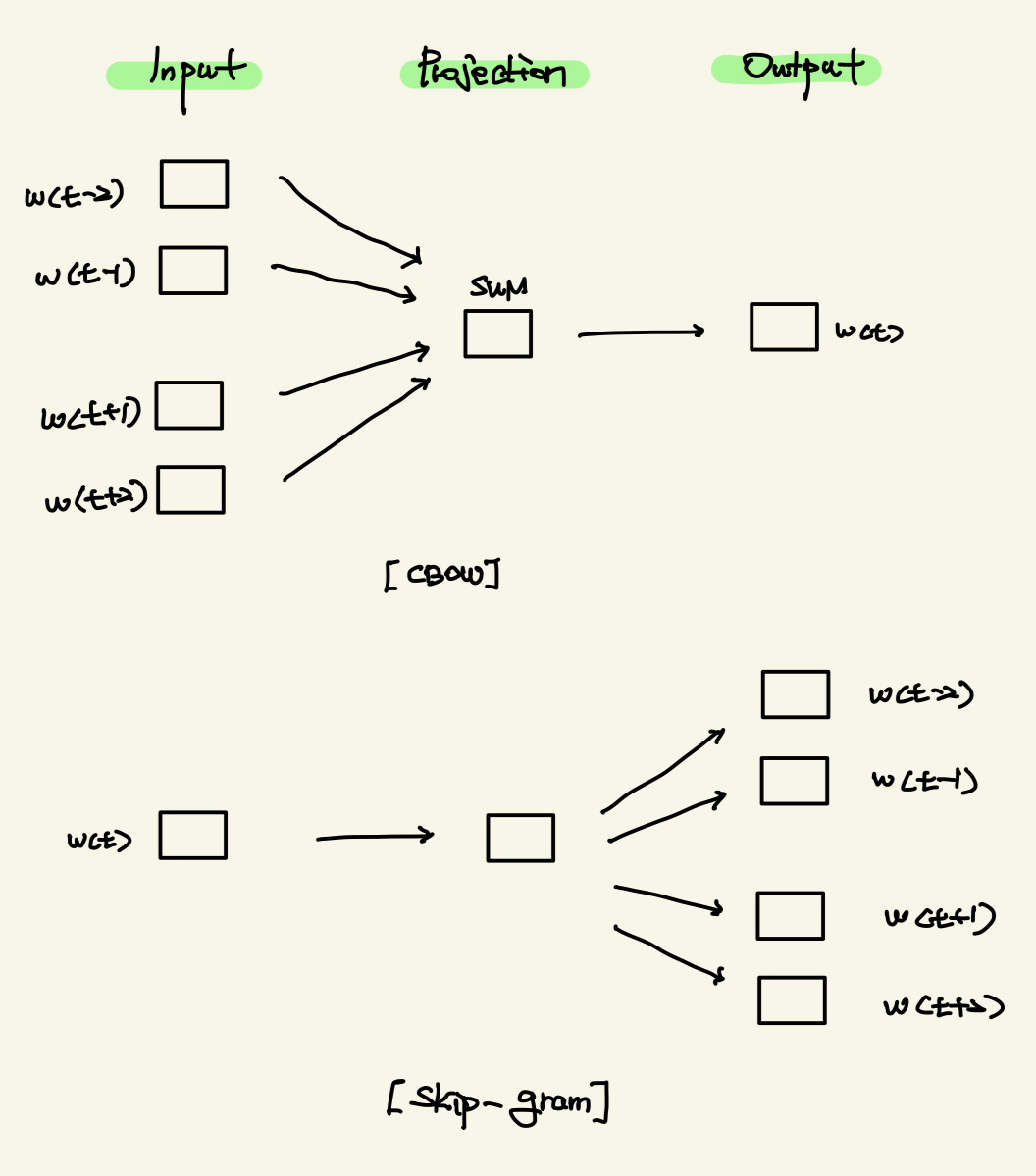 Image of CBOW, Skip-gram
Image of CBOW, Skip-gram
CBOW는 특정 단어가 있을 때, 이 단어의 이전 n개의 단어와 이후 n개의 단어로 특정 단어를 예측한다. Skip-gram은 특정 단어가 주어졌을 때, 이 단어의 이전 n개의 단어와 이후 n개의 단어를 예측한다.
예를 들어, “I”, “love”, “eating”, “chicken”이라는 문장이 있다고 가정하고 중심 단어가 “eating”이라고 가정해 보자. 다음과 같은 프로세스로 CBOW는 예측을 진행한다.
- 주변 단어들(“I”, “love”, “chicken”)을 one-hot encoding을 통해 벡터로 변환한다.
- 나온 벡터들의 평균을 계산한다.
- 평균 벡터를 은닉층 가중치 행렬과 곱하여 임베딩 벡터를 만든다.
- 임베딩 벡터를 출력층 가중치 행렬과 곱샇여 점수 벡터를 만든다.
- 점수 벡터에 softmax 함수를 적용하여 확률 분표를 계산한다.
- 가장 높은 확률을 가진 단어를 예측된 중심 단어로 선택한다.
Skip-gram은 같은 프로세스를 주변 단어 “I”, “love”, “chicken”이 아니라 중심단어 “eating”을 one-hot encoding을 하여 같은 프로세스로 진행된다.
GloVe
Word2Vec과 함께 가장 많이 쓰이는 단어 단위 임베딩 기술이다. 기본 아이디어는 ‘단어 쌍들의 동시 발생 빈도를 기반으로 단어 벡터를 학습한다’이다. 예시를 함께 보면 훨씬 이해가 쉬울 것이다.
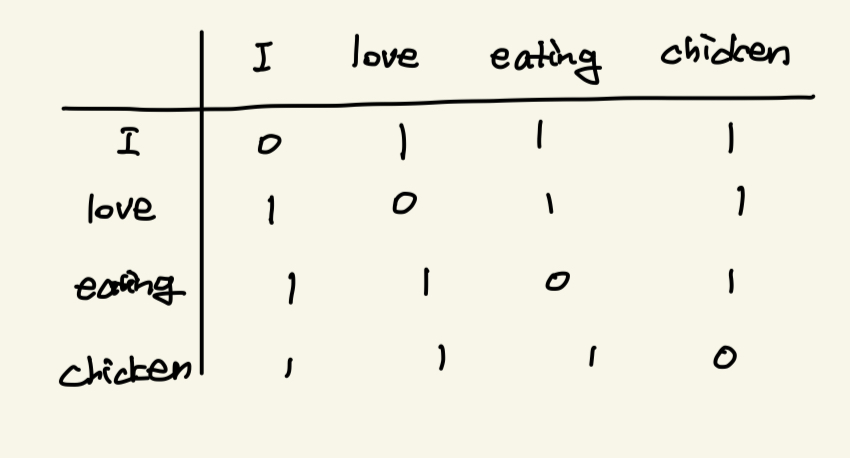 GloVe 동시 발생 행렬 예시
GloVe 동시 발생 행렬 예시
- 텍스트를 읽고 각 단어 쌍이 얼마나 동시에 발생하는지(붙어있는지)에 대한 행렬을 만든다.
- “eating”과 “chicken” 등이 몇 번 같이 나왔는지를 나타내는 동시 발생 행렬의 값을 바탕으로 각 단어의 벡터를 생성한다. 이 벡터들은 숫자들의 리스트로, 단어의 의미를 담고 있다.
- 벡터를 통해(수식활용) 비슷한 의미를 가진 단어들의 벡터가 서로 가깝게 위치하도록 한다.
- 빈도가 드문 단어쌍은 가중치를 덜 주어서 중요한 단어 쌍이 잘 반영되도록 한다.
Conclusion
Word Embedding 방식인 Word2Vec과 GloVe를 통해 텍스트 데이터를 수치 데이터로 변환하여 모델의 input등으로 활용할 수 있게 되었다. Word2Vec과 GloVe는 단어 의미 벡터를 생성하는데 큰 의의가 있다.
하지만, 위 모델들은 단어의 순서를 고려하지 않는다. 즉, ‘I love eating chiken’이나 ‘I eating love chicken’이나 같은 값의 벡터로써 추출될 것이다.
따라서, 이러한 문제점을 개선하기 위해 문장 순서를 고려하는 RNN, LSTM 등의 모델이 임베딩 모델로 제안되었다.
이는 다음 글들에서 다뤄보도록 하겠다.