LLM 정리
LLM, sLLM
배경 지식
RNN
- 텍스트 상에 예측해야 할 빈칸이 존재하면 맥락을 압축하여 잠재상태로 만든 다음 빈칸을 예측하는 방식임.
- 앞에서부터 순차적으로 처리함.
- 즉, 제일 앞의 단어부터 하나씩 쌓으면서 맥락을 이해하는 형태라 긴 문장의 경우 앞 부분의 의미하 희미해 질 수 있는 단점이 존재함.

Attention(in transformer)
- 텍스트(각 토큰들)를 병렬적으로 세운 후 이를 attention을 통한 가중치 부여를 통해 빈칸을 예측하는 방식임.
- 학습 속도와 성능 면에서 장점이 있지만 연산량이 많다는 단점이 존재함.
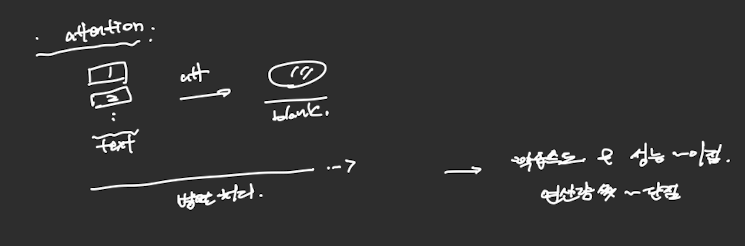
용어 정리(in LLM)
- sequence : 작은 단위(단어)의 다양한 길이의 데이터가 연결되어 있는 것
- sLLM : 좀 더 작은 크기의 모델로 특정 domain과 task에 적합한 모델이라 볼 수 있음.
- LLM 환각 현상 : LLM 모델이 잘못되거나 없는 정보를 만들어내는 과정 -> 이는 RAG(Retrival Augmented Generation)으로 개선할 수 있음.
- parameters : 모델 내부에서 학습을 통해 조정되는 수많은 숫자(bias etc)을 말함. 즉, “어떤 단어가 주어지면 다음에 어떤 단어가 올 확률이 높은지?” 등을 결정하기 위해 사용되는 행렬 형태의 가중치들을 파라미터라 할 수 있음. 모델이 입력을 받으면, 이 파라미터들을 사용해 연산을 수행하고 최종적으로 텍스트를 생성하거나 예측에 사용됨.
- downstream task: pre-trained model을 fine-tunning해서 풀고자 하는 task.
etc
Meta(Llama2)
- 10TB (텍스트) -> Llama2 70B model로 train -> 140GB의 모델 파라미터를 생성하는데 이는 train data에 있던 text 생성의 패턴을 압축하는 모델임.
모델의 발전
- Word2Vec(2013) - Transformer(2017) - GPT-1(2018) - GPT-2(2019) - GPT-3(2020) - ChatGPT(2022) - GPT-4o(2024)
- 여기서 GPT-3 이전까지는 user가 한 다음 말을 생성하는 정도로만 사용되었는데, 이후에는 supervised fine tunning과 RLHF를 통해 사용자와 상호작용 할 수 있는 모델로 업그레이드 됨.
- 이 때, supervised fine tunning을 하기 위한 핵심적인 기법이 alignment(정렬)로 LLM이 생성하는 답을 user의 요청 의도에 맞추는 것을 의미함.
- instruction data
Future work with LLM
- Multimodal LLM(GPT-4o, gemini, Anthropic, Claude…), Multimodal RAG.
- Agent(AutoGPT, AutoGen, crewAI)
- Transformer -> Another architecture로 변환, 더 긴 입력을 효율적으로 처리할 수 있도록..
This post is licensed under CC BY 4.0 by the author.