Matrix Factorization 논문 리뷰
Matrix Factorization Techniques for Recommender Systems (Koren et al., 2009)
Summarization
- 본 논문은 전통적인 추천 방식인 CB, CF의 데이터 희소성, 콜드 스타트 문제의 한계점을 개선하고자 함.
- 사용자-아이템의 평점 데이터를 행렬로 구성하여 이를 잠재요인 공간에 분해 후 내적하는 방식으로 사용자가 새로운 아이템에 부여할 평점을 예측하는 모델인 Matrix Factorization(MF)를 제안함.
Introduction
- 정보 과부화에 따라 사용자에게 만족감을 줄 수 있는 가장 적절한 아이템을 매칭해주는것이 중요해짐.
- 이에, Amazon이나 Netflix 같은 회사에서는 사용자의 선호도에 맞는 아이템을 제공해주는 추천 시스템을 도입하였음.
- 추천 시스템에는 크게 Content filtering과 Collaborative filtering으로 나뉨.
Content Filtering
- 우선, 사용자나 아이템에 대한 특징을 포착할 수 있게 프로필을 생성함
ex. 영화의 프로필의 경우 A 영화를 특정하기 위한 장르, 배우, 박스 오피스 순위 등을 프로필로 구성할 수 있음.- 이러한 프로필을 기반으로 사용자에게 적절한 아이템을 추천해 주는것이 해당 방법임.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
>#### Collaborative Filtering
- 거래 내역이나 제품 평가 등 과거 사용자 행동을 기반으로 추천을 진행하는 방식.
- 사용자 간의 관계와 제품 간의 상호 의존성을 분석하여 새로운 사용자-아이템 연관성을 식별하고자 함.
- 크게 두 방식으로 나뉨
>##### Neighborhood methods
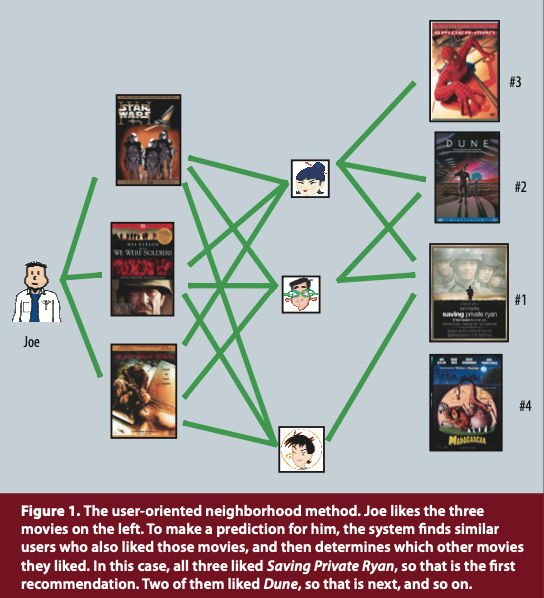
- 그림과 함께 설명하자면,
1. Joe가 관심있어하는 A,B,C 영화가 존재함.
2. 각 영화를 선호하는 다른 사용자들을 확인함.
3. 해당 사용자들이 본 영화들을 확인해서 이 중 Joe가 보지 않았던 영화를 추천해 주는 방식임.
- 즉, 사용자들(neighborhood) 간의 연결성을 통해서 추천을 진행해 주는 방식임.
>##### Latent factor models
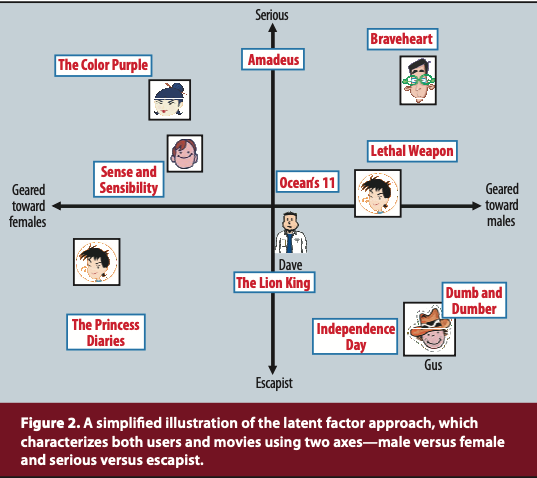
- 평점 패턴으로부터 추출 된 20-100개의 요인(factor)들을 통해 사용자와 아이템에 부여된 평점을 설명하고자 함.
- 잠재 요인 모델은 영화같은 경우 장르, 액션의 정도, orientation to children(어린이들을 대상으로 한지)와 같은 명확한 특성부터 캐릭터의 깊이, 독특함과 같은 추상적 특성까지 다양한 차원을 분석함.
- 각 요인들은 사용자가 해당 특성을 가진 영화를 얼마나 선호하는지를 보여줌.
- 그림은 잠재 요인에 따른 사용자와 아이템을 잠재 공간에 매핑한 상태임
- Gus같은 경우는 Escapist하고 Geared toward males한 요인을 가진 Independence day나 Dumb and Dumber 같은 영화를 선호하는 것을 의미함
>#### Matrix Factorization Methods
- 위에서 언급한 Latent factor model을 기반으로 한게 MF임.
- 추천 시스템은 평점과 같은 explicit data(명시적 데이터)를 주로 사용했는데, 사용자는 모든 아이템에 평점을 부여하는 것이 아니기 때문에 이러한 평점 데이터는 sparse(희소)할 수 밖에 없음.
-
This post is licensed under CC BY 4.0 by the author.